
GTC 2026 Made the AI Stack Easier to See. It Also Exposed the Missing Layer

Scalium
>
Insights
>
Blog
>
GTC 2026 Made the AI Stack Easier to See. It Also Exposed the Missing Layer
At GTC 2026, NVIDIA did more than launch new infrastructure. It gave the market a clearer way to think about AI systems. Jensen Huang framed AI factories around token economics, energy efficiency, and production-scale inference. NVIDIA also introduced the Vera Rubin DSX AI Factory reference design around maximum token per watt, and positioned Dynamo as the inference operating system for AI factories.
That mattered because the rest of the ecosystem showed up with adjacent pieces of the same puzzle. VAST carried its VAST FWD narrative into GTC week, continuing to push a fully accelerated AI data stack and a broader AI OS spanning data services, retrieval, analytics, and agentic workflows. WEKA used GTC to push NeuralMesh AIDP, its AI Data Platform built around enterprise AI factory deployment and continuous data-loop performance. Hammerspace launched an AI Data Platform built around in-place access, global orchestration, and delivery of distributed data to GPUs across hybrid environments.
Seen together, those announcements made something visible that used to stay blurry. The AI stack is no longer one vague “data platform” layer. It is splitting into parts with different jobs. NVIDIA is defining more of the compute base and inference runtime. VAST and WEKA are pushing hard on storage, context, and data services. Hammerspace is claiming the orchestration plane, meaning the logic that keeps data where it belongs and moves only what is needed. That is a real shift in how the market now talks about AI infrastructure.
One useful way to frame the stack now looks like this:
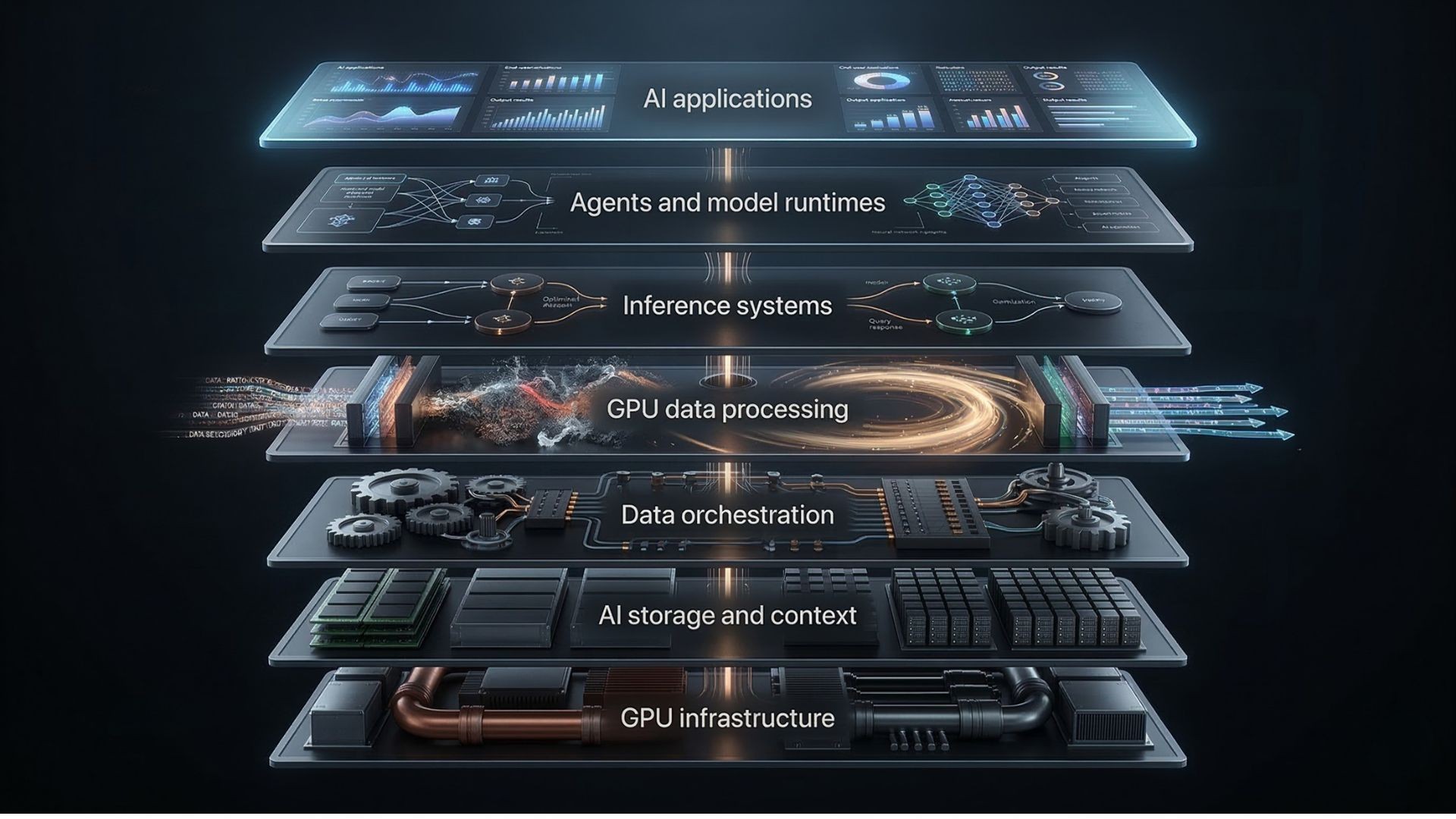
This is not yet a universal industry taxonomy. It is a useful way to separate problems that often get mixed together. Storage is not orchestration. Orchestration is not inference. And inference is not the same as preparing data for inference. That last point is where things get interesting.
The missing piece is not access to data alone. It is execution on the path between data and models. Before a model answers a question, ranks a result, refreshes a feature set, or powers an agent, data usually still needs to be filtered, joined, transformed, vectorized, packaged, and delivered in the format and speed the GPU runtime expects. That work has not gone away. In many enterprises, it still sits in CPU-heavy pipelines built for an earlier era. SCAILIUM’s argument is that storage vendors solve access, orchestration vendors solve location and flow, but the system that processes data at GPU speed before inference still feels under-defined as its own layer.
This matters more now because the workloads have changed. RAG, or retrieval-augmented generation, pulls external facts into model answers. Agentic systems reason step by step, use tools, and act across workflows. Training loops, batch scoring, RAG pipelines, and agentic inference each touch data in different ways. NVIDIA’s GTC announcements also pointed to the agentic AI runtime layer. NVIDIA described NemoClaw as an open source stack for running OpenClaw always-on assistants more safely, with OpenShell as the secure runtime environment, while Dynamo is positioned as the inference operating system for AI factories. That raises the bar for the data path underneath. It is no longer enough to move files quickly. The stack has to support multi-step execution with low latency and strong control.
To be fair, the boundaries are already starting to blur. VAST now talks about faster data preparation, transformation, and pipeline operations inside its broader AI OS story. WEKA is also stretching up the stack by talking about AI factories, continuous context, and turnkey deployment. Hammerspace says it automates the production of AI-ready data. So the strongest claim is not that these companies stay in neat boxes. They do not. The stronger claim is that the market conversation still does not center on a distinct, cross-framework GPU execution layer that turns enterprise data into model-ready input across many workload types.
That is why SCAILIUM has an opening to reframe itself. Not as another platform that tries to own everything. Not as a storage vendor. Not as an orchestrator. Not as model serving. The better frame is narrower and more useful: the GPU-native execution layer, or the compute layer of the AI data pipeline. In that role, SCAILIUM sits between storage and model runtimes and focuses on one hard problem, executing the full data path at GPU speed so compute does not sit idle waiting for CPU-era preparation steps. That position also makes partnership logic easier to explain. With WEKA, the story becomes storage and memory plus execution. With Hammerspace, it becomes orchestration plus execution. With NVIDIA, it becomes runtime plus execution.
This framing is powerful now for three reasons. First, the market already accepts the AI factory premise. Second, NVIDIA has pushed inference to the center of enterprise value. Huang said, “Inference is the engine of intelligence, powering every query, every agent and every application.” That is a clean summary of where budgets and urgency are moving. Third, energy is now part of the architecture conversation, not a side issue. NVIDIA’s DSX reference design talks about maximizing token per watt, and that changes how people judge bottlenecks. If your execution path wastes power and leaves GPUs waiting, that is no longer a tuning issue. It is a business issue.
The bigger takeaway from GTC is not that one company won the stack. It is that the stack became easier to see. That is good for buyers, partners, and builders. It helps everyone ask better questions. Who stores the data? Who orchestrates it? Who runs inference? Who governs agents? And who turns raw enterprise data into model-ready input at GPU speed across real production workloads?
That last question still needs a clearer answer.
Our view is that this is where the next layer of AI infrastructure will take shape. The companies that matter most in the next phase will not be the ones that claim every layer. They will be the ones that make each layer work cleanly with the others, and remove the bottlenecks that still sit between data and useful intelligence. At GTC 2026, the market did not solve that problem. But it finally made it visible.

The SCAILIUM Team at GTC
